
技能指北 | 🦙 MacBookPro上使用Docker和Ollama部署RagFlow与DeepSeek完全指北

技能指北 | 🦙 MacBookPro上使用Docker和Ollama部署RagFlow与DeepSeek完全指北
GnaixEuy
一、为什么需要本地部署大模型?
在AI技术蓬勃发展的今天,RAG(Retrieval-Augmented Generation)架构已成为企业级AI应用的主流方案。通过本地部署RagFlow+DeepSeek组合,开发者可以获得:
- 数据安全性:敏感数据无需上传第三方服务器
- 响应速度:本地网络延迟趋近于零
- 定制化能力:自由调整模型参数与检索策略
- 成本控制:避免按次计费的云服务成本
本教程将基于Apple Silicon架构(M2 Pro芯片)演示完整部署流程。
二、环境准备
硬件配置
- MacBook Pro 14” 2023
- Apple M2 Pro芯片(12核CPU/19核GPU)
- 32GB统一内存
- 1TB SSD
软件要求
1 | # 验证系统版本 |
Docker配置优化
1 | # 创建专属Docker配置 |
三、部署RagFlow智能文档引擎
1. 获取官方镜像
1 | git clone https://github.com/infiniflow/ragflow.git |
2. 启动容器服务
1 | docker compose -f docker/docker-compose.yml up -d |
3. 验证部署
1 | # 查看运行日志 |
四、使用Ollama部署DeepSeek大模型
1. 安装Ollama
1 | brew install ollama --cask |
2. 启动Ollama服务
1 | ollama serve |
3. 下载并运行DeepSeek模型
1 | ollama pull deepseek-r1:7b |
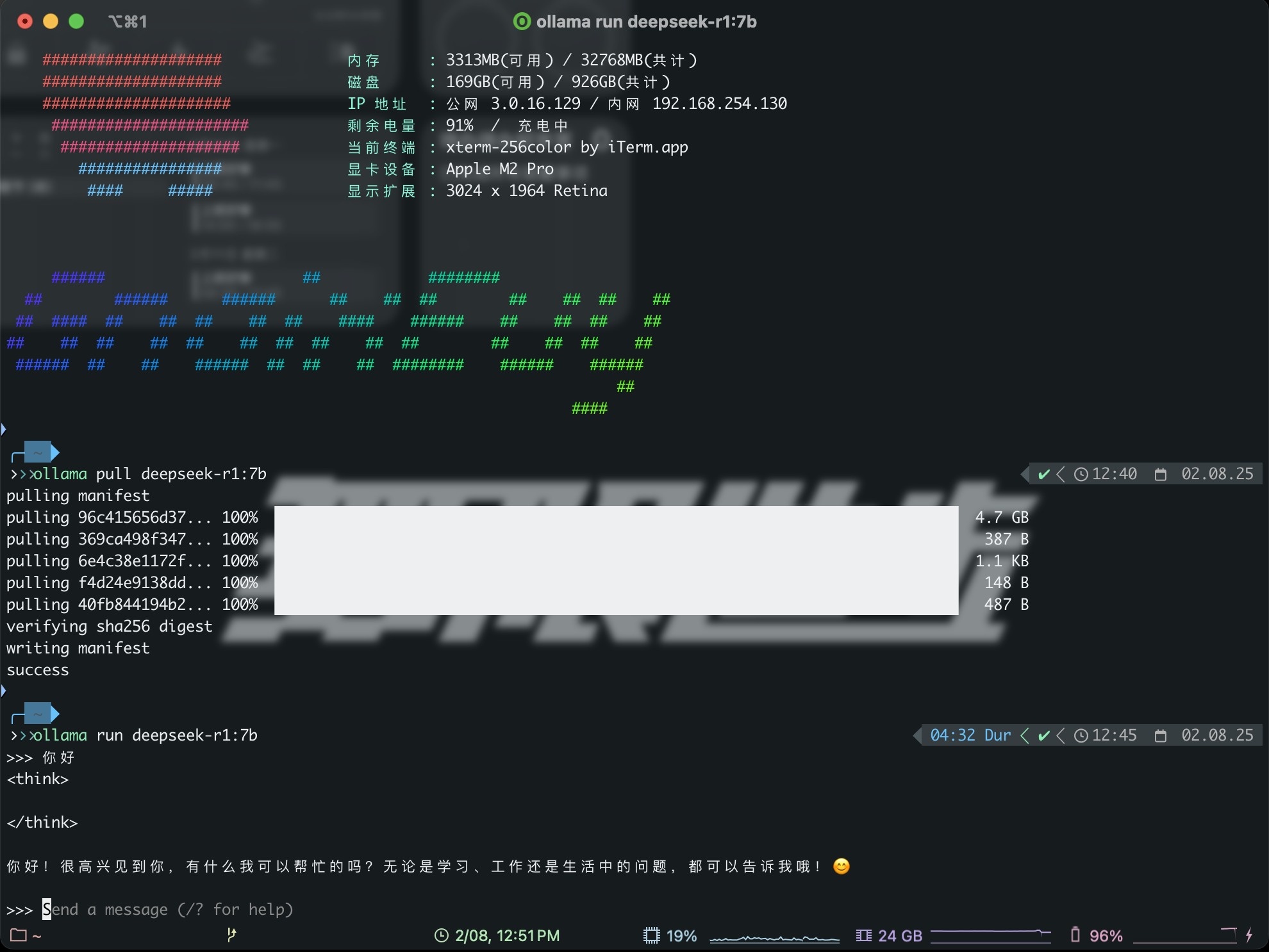
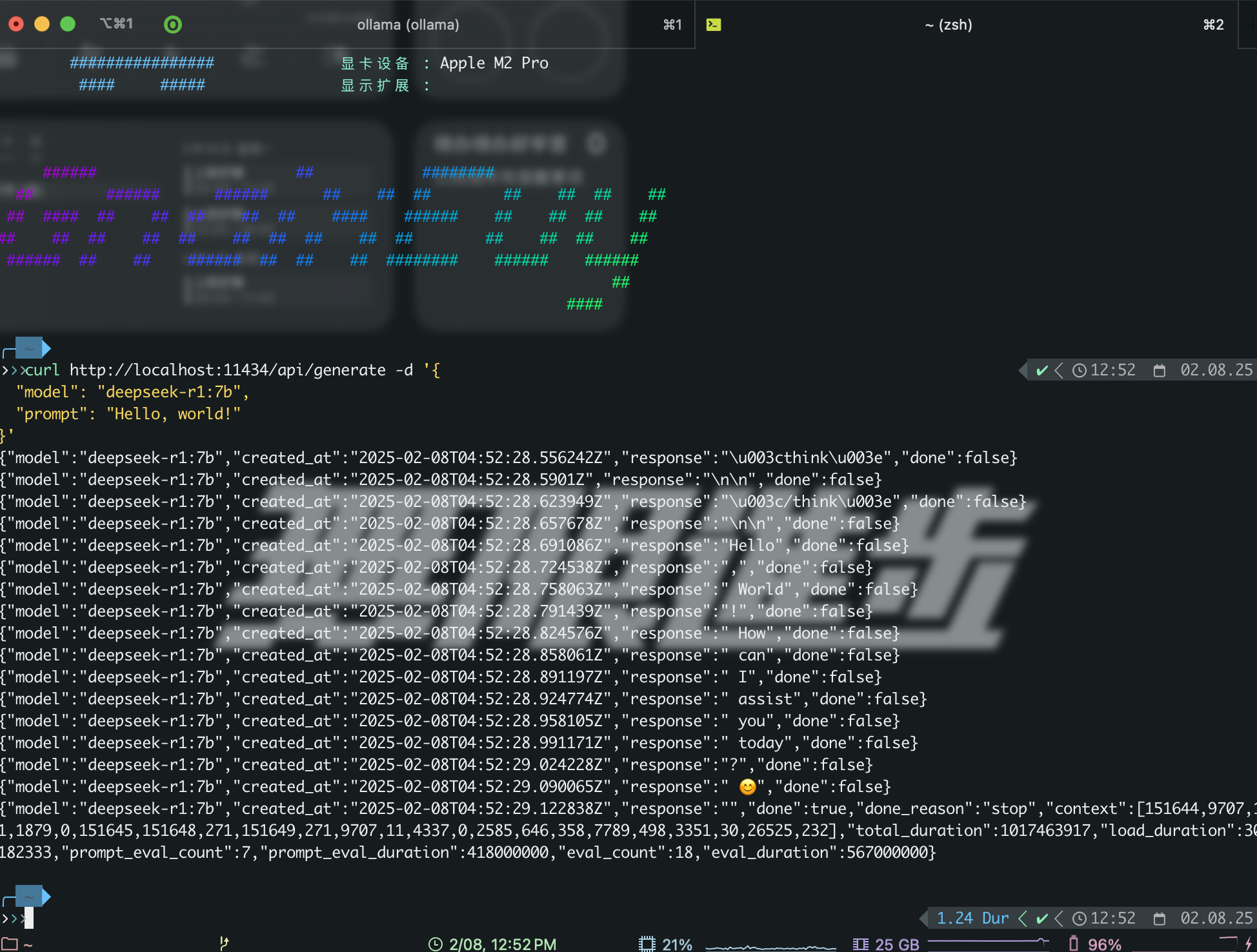
4. 验证部署
1 | curl http://localhost:11434/api/generate -d '{ |
五、配置RagFlow使用DeepSeek后端
1. 登录RagFlow管理界面
- 访问
http://localhost:9380 - 使用默认账号登录(admin/admin)
2. 配置LLM后端
- 进入「系统设置」->「模型配置」
- 选择「自定义模型」
- 填写以下配置:
- 模型名称:DeepSeek
- API地址:
http://localhost:11434 - 模型类型:Ollama
- 模型路径:
deepseek
3. 测试连接
- 点击「测试连接」按钮
- 确保返回状态为「连接成功」
4. 创建知识库
- 进入「知识库管理」
- 点击「新建知识库」
- 选择DeepSeek作为默认LLM
- 上传文档或连接数据源
六、常见问题排查
问题1:Docker容器内存不足
现象:容器频繁重启
解决方案:
1 | docker update --memory=24g --memory-swap=32g ragflow-server |
问题2:Ollama服务异常
现象:模型无法加载
调试命令:
1 | ollama logs |
问题3:RagFlow连接失败
检查步骤:
- 确认Ollama服务正在运行
- 检查防火墙设置
- 验证API地址是否正确
七、项目价值与面试应用
完成本部署方案后,你将在技术面试中展现:
- 全栈工程能力:从容器化部署到模型优化的完整链路
- 架构设计思维:RAG架构的实践落地经验
- 性能调优经验:Apple Silicon生态的优化技巧
- 问题解决能力:本地部署的典型问题处理
建议将本项目纳入简历的「开源贡献」或「个人项目」板块,并准备以下面试问题:
- 如何平衡本地部署的硬件成本与性能需求?
- RAG架构相比纯LLM方案的优势与局限?
- 在ARM架构上部署AI模型的注意事项?
延伸学习:
部署完成后,你已拥有一个企业级的本地知识处理系统。建议后续可接入私有知识库或开发可视化界面,打造完整的AI应用解决方案。


喜欢这篇文章的人也看了



评论
匿名评论隐私政策
✅ 你无需删除空行,直接评论以获取最佳展示效果










